Alignment
Post-Editing for Machine Translation
Post-editing is a process carried out by a Language Specialist to proofread machine-translated texts before they are published. This service has been developed for businesses which have incorporated machine translation solutions into their processes.
Even with careful linguistic and technical preparation, most translations made by machines are not without their flaws – we therefore highly recommend having a language expert who is trained and experienced in post-editing check through the content.
An advantage to this process is also the opportunity to evaluate the quality of the machine translation. This makes it possible to evaluate how suitable the data in the machine translation engine, known as the corpus, has been in the past and how it is developing.
A process can also be set up to continuously improve the reliability and quality of the corpus by correcting faulty or unsuitable segments.

The precise structure of a post-editing process is established on an individual basis. We rely on workflows developed specifically for this purpose, as well as on the specifications of the post-editing standard ISO 18587.
tsd would be happy to advise you on post-editing for machine translations and plan out an individualised solution for your company. Simply contact us via telephone on +49 (0)221 92 59 86 0 or via email at tsd@tsd-int.com.
Standard workflow
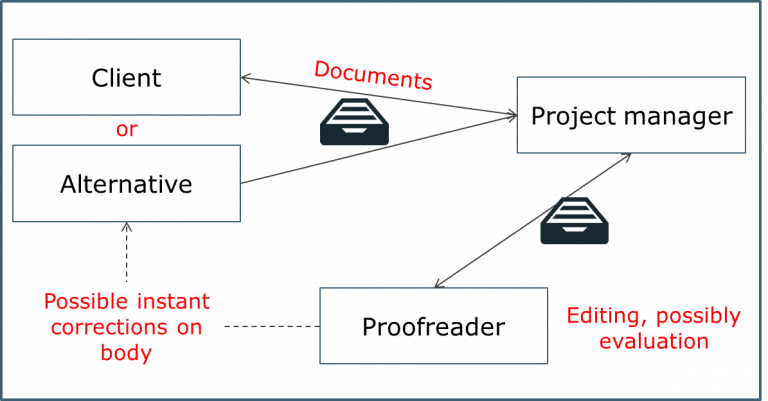
- The tsd project manager receives the partially or fully machine-translated documents or carries out the machine translation themselves.
- They pass this on to the post-editor, who checks and edits the translation. Depending on the workflow, the post-editor works directly in the machine translation tool, translation management system or text files. Whether or not corrections are then entered into the corpus is decided on an individual basis.
- After completing the work, the post-editor sends the edited documents and, if relevant, a quality evaluation of the machine translation back to the project manager. If necessary, feedback on the source text is also given.
- The project manager delivers the content to the customer.
Checklist
